Measuring std::memmove speed
I wrote a simple test that outputs std::memmove speed to the console:
AWT_ATTRIBUTE(size_t, element_count, 1000000);
std::unique_ptr<uint8_t> p_src(new uint8_t[element_count]);
std::memset(p_src.get(), 25u, element_count);
std::unique_ptr<uint8_t> p_dst(new uint8_t[element_count]);
context.out << _T("std::memmove: ");
awl::StopWatch w;
std::memmove(p_dst.get(), p_src.get(), element_count);
ReportSpeed(context, w, element_count);
context.out << std::endl;
And the similar tests for std::memset and std::vector::insert.
The possible test results on my home machine with Intel i7-9700 CPU, Windows 10 and MSVC 2017 can be:
AwlTest.exe --output all --filter VtsMem.* --element_count 10000000
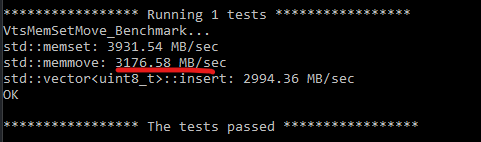
AwlTest.exe --output all --filter VtsMem.* --element_count 1000000
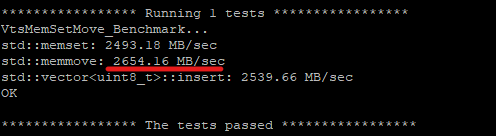
std::memmove speed varies from 2900 MB/sec to 3900.00 MB/sec across multiple test runs (source and destination buffers are not in the processor cache, because std::memmove is executed one time).
Measuring the serialization performance
Writing speed
I write A1 and B1 structures instances into a stream with the following code:
struct A1
{
int a;
double b;
std::string c;
AWL_REFLECT(a, b, c)
};
struct B1
{
int x;
bool y;
AWL_REFLECT(x, y)
};
static const A1 a1_expected = { 1, 2.0, "abc" };
static const B1 b1_expected = { 1, true };
template <class OutputStream>
std::chrono::steady_clock::duration WriteDataV1(OutputStream & out, size_t element_count, bool with_metadata)
{
OldContext ctx;
ctx.Initialize();
{
auto & a1_proto = ctx.FindNewPrototype<A1>();
AWT_ASSERT(a1_proto.GetCount() == 3);
auto & b1_proto = ctx.FindNewPrototype<B1>();
AWT_ASSERT(b1_proto.GetCount() == 2);
}
if constexpr (std::is_base_of_v<awl::io::SequentialOutputStream, OutputStream>)
{
if (with_metadata)
{
ctx.WriteNewPrototypes(out);
}
}
else
{
assert(!with_metadata);
static_cast<void>(with_metadata);
}
awl::StopWatch w;
for (size_t i : awl::make_count(element_count))
{
static_cast<void>(i);
awl::io::WriteV(out, a1_expected, ctx);
awl::io::WriteV(out, b1_expected, ctx);
}
return w;
}
And use a specific test stream with WriteArithmetic function:
class MemoryOutputStream
{
public:
MemoryOutputStream(size_t size) : m_size(size), pBuf(new uint8_t[size]), m_p(pBuf)
{
std::memset(pBuf, 0u, m_size);
}
~MemoryOutputStream()
{
delete pBuf;
}
constexpr void Write(const uint8_t * buffer, size_t count)
{
StdCopy(buffer, buffer + count, m_p);
m_p += count;
}
template <class T>
std::enable_if_t<std::is_arithmetic_v<T>, void> WriteArithmetic(const T val)
{
uint8_t * const new_p = m_p + sizeof(val);
if (static_cast<size_t>(new_p - pBuf) > m_size)
{
throw GeneralException(_T("overflow"));
}
*(reinterpret_cast<T *>(m_p)) = val;
m_p = new_p;
}
size_t GetCapacity() const
{
return m_size;
}
size_t GetLength() const
{
return m_p - pBuf;
}
void Reset()
{
m_p = pBuf;
}
private:
const size_t m_size;
uint8_t * pBuf;
uint8_t * m_p;
};
Usually we specialize awl::io::Write template function for a type being serialized, but I also specialized awl::io::Write for my concrete stream as follows:
template <typename T>
inline std::enable_if_t<std::is_arithmetic_v<T> && !std::is_same_v<T, bool>, void> Write(MemoryOutputStream & s, T val)
{
s.WriteArithmetic(val);
}
template <>
inline void Write(MemoryOutputStream & s, bool b)
{
uint8_t val = b ? 1 : 0;
s.WriteArithmetic(val);
}
thus I speed up the serialization of arithmetic types due to the fact that their sizes are known at compile time and so m_p is increased by a constant and they are copied without looping.
Finally I test the serialization with a code like this:
AWT_TEST(VtsWriteMemoryStreamConstexpr)
{
AWT_ATTRIBUTE(size_t, element_count, 1000000);
AWT_ATTRIBUTE(size_t, iteration_count, 1);
const size_t mem_size = MeasureStreamSize(context, element_count, false);
MemoryOutputStream out(mem_size);
{
std::chrono::steady_clock::duration total_d = std::chrono::steady_clock::duration::zero();
for (auto i : awl::make_count(iteration_count))
{
static_cast<void>(i);
total_d += WriteDataV1(out, element_count);
AWT_ASSERT_EQUAL(mem_size, out.GetCapacity());
AWT_ASSERT_EQUAL(mem_size, out.GetLength());
out.Reset();
}
context.out << _T("Test data has been written. ");
ReportCountAndSpeed(context, total_d, element_count * iteration_count, mem_size * iteration_count);
context.out << std::endl;
}
}
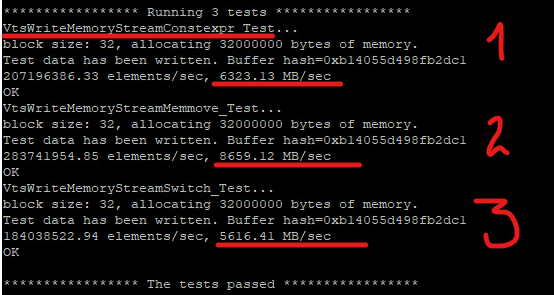
If I run this test along with two others:
AwlTest --output all --filter VtsWriteMemoryStream.* --element_count 10000000 --iteration_count 1
I get this:

On the above picture our VtsWriteMemoryStreamConstexpr test goes 1st, its speed is 2522 MB/sec that is about 70% of std::memmove. A stream with virtual Write function that calls std::memmove is at the 2nd place. And at the 3rd place a stream that does switch on the arithmetic type size in its Write method.
One million of elements is enough for testing, with 10 millions we get the same results, but it is not clear why the speed does not grow with the number of iterations.
Notes about used functions
- As you probably noted I use StdCopy function:
constexpr void StdCopy(const uint8_t * begin, const uint8_t * end, uint8_t * out)
{
const uint8_t * p = begin;
while (p != end)
{
*out++ = *p++;
}
}
it is because std::copy is not constexpr in C++17 yet, but it will be in C++20.
- And also I use MeasureStreamSize function that calculates stream buffer size using awl::io::MeasureStream.
- ReportSpeed and ReportCountAndSpeed are the functions that calculate the speed and output it into the console.
Source code
The full source code of the serialization framework and the test is available on GitHub as a part of AWL library.
Compiling with GCC 7
On my Hyper-V virtual machine with Ubuntu 18.04 I installed GCC 7.0, CMake and compiled AWL:
sudo apt install gcc g++
g++ --version
sudo apt install cmake
git clone https://github.com/dmitriano/Awl.git
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Release ../Awl/
make -j2
./AwlTest --output all --filter VtsWriteMemoryStream.* --element_count 1000000 --iteration_count 1
If I compile with -O3 option (default is -O0):
cd build
rm -rf *
cmake -E env CXXFLAGS="-O3" cmake -DCMAKE_BUILD_TYPE=Release ../Awl/
make -j2
./AwlTest --output all --filter VtsWriteMemoryStream.* --element_count 1000000 --iteration_count 1
the result is a bit different:
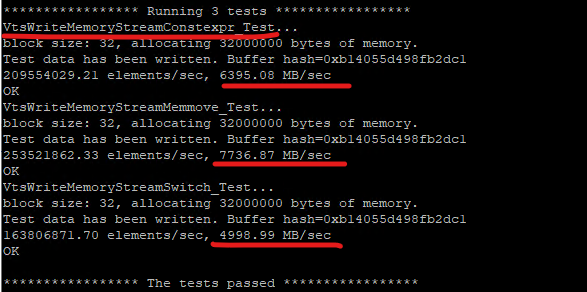
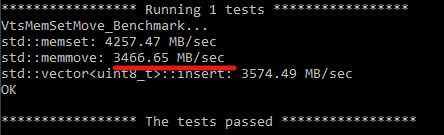
./AwlTest --output all --filter VtsMem.* --element_count 10000000
so with GCC the serialization is faster than std::memmove in 155%, but I can’t explain why 2 and 3 is even faster, probably it is something related to the processor cache or some nonsense happens 🙂
Note that MSVC and GCC produce equal buffer hashes so it is more likely that it works than glitches 🙂
Compiling with GCC 9
apt update
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt install gcc-9 g++-9
update-alternatives --display gcc
ll /usr/bin/gcc-9
ll /usr/bin/g++-9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 10 --slave /usr/bin/g++ g++ /usr/bin/g++-9
g++ --version
gcc --version
cd build
rm -rf *
cmake -DCMAKE_BUILD_TYPE=Release ../Awl/
make -j2
./AwlTest --output all --filter VtsWriteMemoryStream.* --element_count 1000000 --iteration_count 1
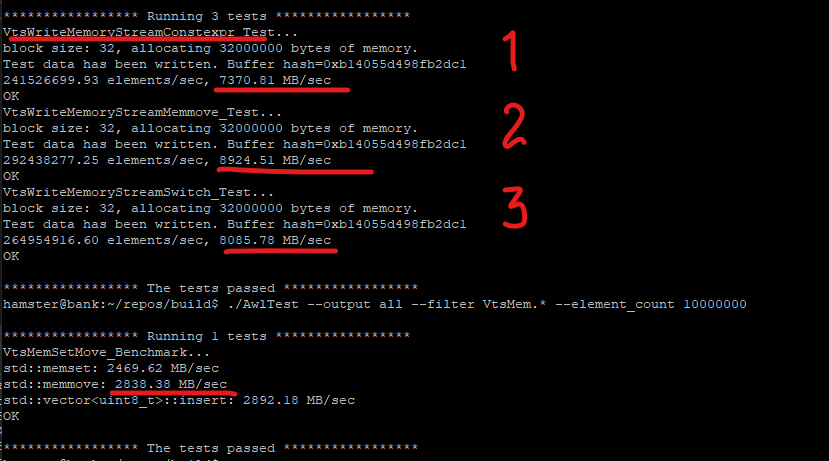
The serialization speed is in 3.14 times faster than std::memmove (π = 8924 / 2838).

